КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Вероятность попадания случайной точки в прямоугольник
|
|
|
|
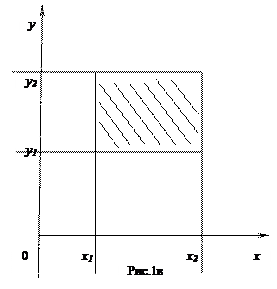
Рассмотрим прямоугольник ABCD со сторонами параллельными координатным осям. Пусть уравнения сторон таковы: X=x1,X=x2,Y=y1 и Y=y2. (рис.1в) Найдем вероятность попадания случайной точки (X,Y) в этот прямоугольник, используя предыдущий раздел:
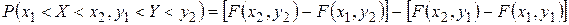 (1)
(1)
Пример 2. Найти вероятность попадания случайной точки (X,Y) в прямоугольник, ограниченный прямыми 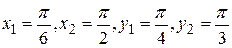 , если известна функция распределения системы.
, если известна функция распределения системы. 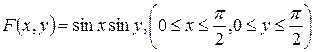 .
.
Решение. Положив в формуле (1), получим 
Рассмотрим теперь непрерывные двумерные случайные величины. Очевидно, что задать непрерывную случайную величину с помощью закона распределения невозможно, требуется либо функция распределения, либо плотность распределения. Плотностью совместного распределения вероятностей f(x,y) двумерной непрерывной случайной величины (X,Y) называют вторую смешанную частную производную от функции распределения:  . Эту функцию можно рассматривать как предел отношения вероятности попадания случайной точки в прямоугольник (со сторонами
. Эту функцию можно рассматривать как предел отношения вероятности попадания случайной точки в прямоугольник (со сторонами 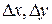 ) к площади этого прямоугольника, когда обе стороны прямоугольника стремятся к нулю.
) к площади этого прямоугольника, когда обе стороны прямоугольника стремятся к нулю.
Зная плотность совместного распределения f(x,y) можно найти функцию распределения F(x,y) по формуле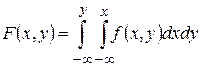 . (2)
. (2)
Пример 3. Найти функцию распределения двумерной случайной величины по данной плотности совместного распределения  .
.
Решение. Воспользуемся формулой (2), получим
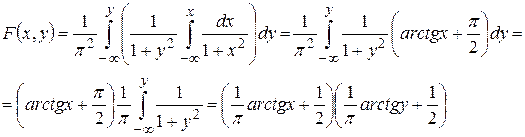
Вероятность попадания случайной точки в произвольную область.
Для того, чтобы вычислить вероятность попадания случайной точки (X,Y) в область D, достаточно найти двойной интеграл по области D от функции f(x,y). 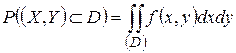 (3)
(3)
Геометрически равенство (3) можно истолковать так: вероятность попадания случайной точки (X,Y) в область D равна объему тела, ограниченного сверху поверхностью z=f(x,y), основанием которого служит проекция этой поверхности на плоскость xOy.
Пример 4. Плотность распределения двумерной случайной величины . Найти вероятность попадания случайной точки в прямоугольник с вершинами К(1,1),М(1,0),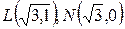 .
.
Решение. Искомая вероятность
Свойства двумерной плотности вероятности.
Свойство 1: Двумерная плотность вероятности неотрицательна: 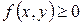
Свойство 2: Двойной несобственный интеграл с бесконечными пределами от двумерной плотности равен единице:  .
.
Отдельным вопросом стоит изучение характера связи между случайными величинами, входящими в систему. Относительно этой связи имеется, в принципе, три возможности.
1) Первая возможность: величины X и Y независимы друг от друга. Это значит, что каждая из этих величин принимает свои значения независимо от значений, принимаемых другой случайной величиной.
2) Вторая возможность - обратная первой: величины Х и Y связаны жесткой (функциональной) зависимостью, т.е. зависимостью вида Y =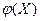 . В этом случае каждому возможному значению величины Y соответствуют вполне определенное значение y =
. В этом случае каждому возможному значению величины Y соответствуют вполне определенное значение y =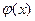 величины Y. То есть возможные значения величины Y жестко привязаны к возможным значениям величины X.
величины Y. То есть возможные значения величины Y жестко привязаны к возможным значениям величины X.
3) Третья возможность - промежуточная между первыми двумя: Х и Y в принципе связаны между собой (независимыми они не являются), но эта связь не жёсткая (размытая). Это значит, что каждому возможному значению х величины Х могут соответствовать различные значения (у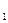 ; у
; у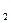 ;...) величины Y, причём набор этих значений и (или) их вероятности меняются с изменением значения х. Такого рода связь между случайными величинами называются статистической (или вероятностной) связью. Статистическая связь между случайными величинами X и Y означает, что изменение значения одной из них ведет к изменению внешних условий для реализации другой величины. Например, меняющаяся среднесуточная температура статистически влияет на плотность сельскохозяйственных вредителей на засеянном поле; объем денежной массы у покупателей статистически влияет на объем закупаемых ими товаров, и т.д.
;...) величины Y, причём набор этих значений и (или) их вероятности меняются с изменением значения х. Такого рода связь между случайными величинами называются статистической (или вероятностной) связью. Статистическая связь между случайными величинами X и Y означает, что изменение значения одной из них ведет к изменению внешних условий для реализации другой величины. Например, меняющаяся среднесуточная температура статистически влияет на плотность сельскохозяйственных вредителей на засеянном поле; объем денежной массы у покупателей статистически влияет на объем закупаемых ими товаров, и т.д.
Если при статистической связи между случайными величинами X и Y при изменении значения х величины X еще и меняется среднее значение 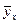 величины Y, то говорят, что Y корреляционно (в среднем) зависит от X. Аналогично понимается корреляционная зависимость X от Y. В частности, очевидно, что между температурой X воздуха и количеством Y вредителей имеет место не просто статистическая, а корреляционная зависимость, ибо с изменением температуры изменяется и среднее количество сельскохозяйственных вредителей. Аналогично между количеством X денег у покупателей и их тратами Y на покупку товаров тоже имеется, очевидно, корреляционная зависимость, ибо чем больше денег у покупателей, тем больше в среднем они покупают. Корреляционно (в среднем) связаны также урожайность различных культур с количеством внесенных под них удобрений, производительность труда рабочих с их квалификацией, и т.д.
величины Y, то говорят, что Y корреляционно (в среднем) зависит от X. Аналогично понимается корреляционная зависимость X от Y. В частности, очевидно, что между температурой X воздуха и количеством Y вредителей имеет место не просто статистическая, а корреляционная зависимость, ибо с изменением температуры изменяется и среднее количество сельскохозяйственных вредителей. Аналогично между количеством X денег у покупателей и их тратами Y на покупку товаров тоже имеется, очевидно, корреляционная зависимость, ибо чем больше денег у покупателей, тем больше в среднем они покупают. Корреляционно (в среднем) связаны также урожайность различных культур с количеством внесенных под них удобрений, производительность труда рабочих с их квалификацией, и т.д.
Рассмотрим корреляционную связь между случайными величинами X и Y подробнее. Пусть - среднее значение тех значений у величины Y, которые соответствуют данному значению x величины X. Оно же - условное математическое ожидание величины Y при X=x:
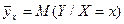 (4)
(4)
Так как каждому возможному значению x величины X будет соответствовать единственное значение , то это значение является функцией от x:
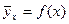 (5)
(5)
 Если меняется с изменением x, то есть если
Если меняется с изменением x, то есть если  , то между X и Y имеется корреляционная связь – Y корреляционно (в среднем) зависит от X. А если
, то между X и Y имеется корреляционная связь – Y корреляционно (в среднем) зависит от X. А если 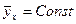 , то Y корреляционно от X не зависит. В последнем случае Y либо вообще не зависит от X, либо зависит, но лишь сугубо статистически.
, то Y корреляционно от X не зависит. В последнем случае Y либо вообще не зависит от X, либо зависит, но лишь сугубо статистически.
Функциональная зависимость (5) называется уравнением регрессии Y на X, а график этой зависимости – линией регрессии Y на X (рис 2):
Линия регрессии Y на X наглядно показывает, как в среднем меняется случайная величина Y при изменении случайной величины X. Точки вокруг линии регрессии символизируют разброс возможных значений y величины Y вокруг линии регрессии . Именно из этих значений y для каждого x должно быть найдено их среднее значение .
Аналогично зависимость вида 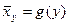 называется уравнением регрессии X на Y, а ее график – линией регрессии X на Y (рис 3)
называется уравнением регрессии X на Y, а ее график – линией регрессии X на Y (рис 3) .
.
Линия регрессии X на Y показывает, как в среднем меняется X при изменении Y.
Самой простой случай (и наиболее часто встречающийся на практике) – это когда функция или линейна, то есть когда её график – прямая линия. В этом случае корреляционная зависимость Y от X и соответственно корреляционная зависимость X от Y называется линейной, в противном случае – нелинейной.
В теории корреляции решаются две основные задачи:
Первая задача теории корреляции - нахождение уравнения регрессии, то есть нахождение зависимости между значениями одной случайной величины и соответствующими им средними значениями другой случайной величины.
Вторая задача теории корреляции – оценка тесноты изучаемой корреляционной зависимости. В частности, теснота корреляционной зависимости Y от Х оценивается по степени рассеяния значений (у; у;....) величины Y (рис.2) вокруг линии регрессии . Большое рассеяние свидетельствует о слабой корреляционной зависимости Y от Х. Наоборот, малое рассеяние указывает на наличие достаточно сильной (тесной) корреляционной зависимости. Возможно даже, что Y зависит от Х функционально, то есть жёстко, но из-за второстепенных случайных факторов или просто из-за погрешностей измерений эта зависимость оказалась несколько размытой.
Те же задачи, естественно, стоят, если исследуется корреляционная зависимость X от Y.
Наиболее просто решаются обе эти задачи при наличии линейной корреляционной зависимости одной случайной величины от другой. И здесь важную роль играет так называемый корреляционный момент  или, что одно и то же, ковариация
или, что одно и то же, ковариация 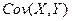 случайных величин Х и Y, которые определяются как математическое ожидание произведения отклонений Х и Y от их математических ожиданий:
случайных величин Х и Y, которые определяются как математическое ожидание произведения отклонений Х и Y от их математических ожиданий:
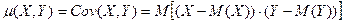 (6)
(6)
Их можно преобразовать к виду (проделайте это самостоятельно):
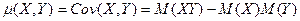 (7)
(7)
Для вычисления корреляционного момента дискретных величин используют формулу 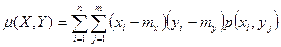 , а для непрерывных величин – формулу
, а для непрерывных величин – формулу 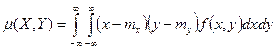 .
.
Как известно, у независимых случайных величин Х и Y, как у дискретных, так и у непрерывных, 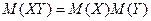 . А значит, для независимых случайных величин
. А значит, для независимых случайных величин
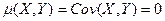 (8)
(8)
Поэтому если 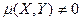 , то это автоматически указывает на зависимость случайных величин Х и Y друг от друга.
, то это автоматически указывает на зависимость случайных величин Х и Y друг от друга.
Отметим, что обратное, вообще говоря, неверно: из того, что корреляционный момент 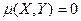 , ещё нельзя сделать вывод, что Х и Y независимы. Они могут быть зависимы, причём даже функционально. Например, если распределение величины Х симметрично относительно точки х =0, так что автоматически
, ещё нельзя сделать вывод, что Х и Y независимы. Они могут быть зависимы, причём даже функционально. Например, если распределение величины Х симметрично относительно точки х =0, так что автоматически 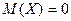 и
и 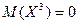 , а
, а 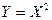 - функция от Х, то на основании (7) получаем:
- функция от Х, то на основании (7) получаем:
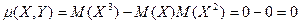
И это несмотря на то, что Х и Y связаны функциональной зависимостью 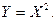
Случайные величины, для которых , называются линейно некоррелированными. Независимые величины всегда линейно некоррелированы. Но линейно некоррелированные величины могут быть, как мы только что видели, как зависимыми, так и независимыми. Линейно коррелированные же величины (для них ) всегда зависимы.
Кстати, если случайные величины X и Y распределены нормально, то можно доказать (на этом не останавливаемся), что их линейная некоррелированность равнозначна их независимости. Для других же величин Х и Y это не обязательно одно и тоже.
Отметим, что корреляционный момент обладает одним существенным недостатком: он зависит от единиц измерения величин X и Y. Поэтому на практике вместо него часто используется безразмерная величина,
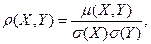 (9)
(9)
которая называется коэффициентом линейной корреляции. Он играет, как мы увидим ниже, большую роль при решении обеих задач теории корреляции в случае линейной корреляционной зависимости между случайными величинами.
Корреляционный момент и коэффициент линейной корреляции 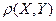 равны или не равны нулю одновременно. Поэтому линейную коррелированность и линейную некоррелированность случайных величин X и Y можно устанавливать и по равенству или неравенству нулю коэффициента линейной корреляции .
равны или не равны нулю одновременно. Поэтому линейную коррелированность и линейную некоррелированность случайных величин X и Y можно устанавливать и по равенству или неравенству нулю коэффициента линейной корреляции .
Так как, согласно (7), 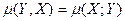 , то и
, то и
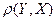 = (10)
= (10)
Коэффициент линейной корреляции обладает еще одним важным свойством: он не изменится, если от X и Y перейти к безразмерным нормированным случайным величинам
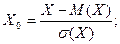
 (11)
(11)
То есть
=  (12)
(12)
Нормированными случайными величинами 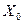 и
и 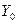 называются потому, что их математические ожидания равны нулю, а средние квадратические отклонения равны единице:
называются потому, что их математические ожидания равны нулю, а средние квадратические отклонения равны единице:
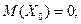
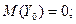
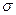 ()=
()=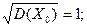 ()=
()=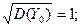 (13)
(13)
Равенства (13) легко доказываются с помощью свойств математического ожидания и дисперсии, которые справедливы как для непрерывных, так и для дискретных случайных величин (проделайте это самостоятельно). Ну, а то, что=, уже вытекает из (6), (7), (9), (11) и (13):

Для дальнейшего рассмотрения свойств коэффициента линейной корреляции случайных величин X и Y найдем дисперсию их суммы X+Y и разности X-Y. Если величина X и Y независимы, то такая формула уже получена:
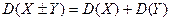 (14)
(14)
Причем эта формула верна как для дискретных, так и для непрерывных случайных величин. А если X и Y зависимы (функционально или статистически), то соответствующая формула имеет вид:
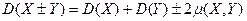 (15)
(15)
Действительно:
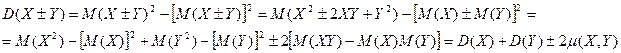
В частности, для нормированных случайных величин 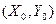 формула (15) примет вид:
формула (15) примет вид:
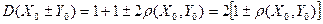 (16)
(16)
А так как, по смыслу дисперсии, 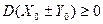 , то из (16) получаем:
, то из (16) получаем:
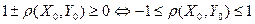 (17)
(17)
И так как, согласно (12), 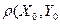 ) = , то для любых случайных величин Х и Y получаем следующий вывод:
) = , то для любых случайных величин Х и Y получаем следующий вывод:
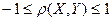 (18)
(18)
Если коэффициент линейной корреляции 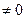 , то он характеризует не только наличие зависимости (связи) между Х и Y. Своей величиной, как мы это сейчас увидим, он характеризует и тесноту этой связи. Однако не любой, а лишь линейной корреляционной связимежду Х и Y. Отсюда и его название – коэффициент линейной корреляции. Максимальная теснота этой связи соответствует случаям, когда
, то он характеризует не только наличие зависимости (связи) между Х и Y. Своей величиной, как мы это сейчас увидим, он характеризует и тесноту этой связи. Однако не любой, а лишь линейной корреляционной связимежду Х и Y. Отсюда и его название – коэффициент линейной корреляции. Максимальная теснота этой связи соответствует случаям, когда  =
= 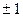 . При этом между Х и Y имеет место жёсткая функциональная связь, причём связь непременно линейная:
. При этом между Х и Y имеет место жёсткая функциональная связь, причём связь непременно линейная: 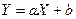 .
.
Действительно, при = и )=, а тогда из (16) вытекает, что имеет место одно из двух равенств: или 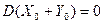 , или
, или 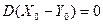 . Но дисперсия случайной величины равна нулю, если только эта случайная величина является константой. То есть или
. Но дисперсия случайной величины равна нулю, если только эта случайная величина является константой. То есть или 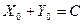 , или
, или  . Заметим, что в обоих случаях константа
. Заметим, что в обоих случаях константа 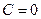 , ибо на основании (13) получаем:
, ибо на основании (13) получаем:
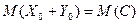

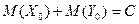
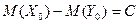
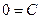
Итак, при = либо 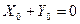 , либо
, либо 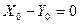 . А отсюда уже, согласно связи (11) с
. А отсюда уже, согласно связи (11) с 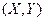 , следует подтверждение того, что в обоих случаях величины Х и Y связаны линейной функциональной зависимостью вида .
, следует подтверждение того, что в обоих случаях величины Х и Y связаны линейной функциональной зависимостью вида .
Верно и обратное: если случайные величины Х и Y связаны линейной функциональной зависимостью , то их коэффициент линейной корреляции равен либо 1, либо -1.
Докажем это. Действительно, если , то согласно (11) и свойств математического ожидания и дисперсии получаем:
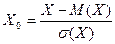 ;
; 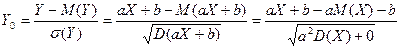 =
=
=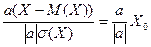 .
.
А тогда
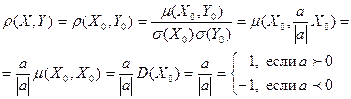
Таким образом, коэффициент линейной корреляции есть показатель того, насколько зависимость между случайными величинами X и Y близка к строгой линейной зависимости . Его малость (удаленность от 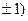 может означать одно из двух: или малую тесноту (большое рассеяние) линейной корреляционной связи между X и Y, или существенную нелинейность этой связи, которая, кстати, может быть весьма тесной.
может означать одно из двух: или малую тесноту (большое рассеяние) линейной корреляционной связи между X и Y, или существенную нелинейность этой связи, которая, кстати, может быть весьма тесной.
Сформулируем это утверждение более определенно. Найдем такие числовые коэффициенты k и b, чтобы линейная функция кX+b случайной величины X наилучшим образом приближала случайную величину Y. Для этого представим Y в виде
Y=кX+b+Z (19) Случайную величину Z можно рассматривать как ошибку приближения величины Y линейной функцией Y=кX+b. Эту ошибку естественно считать минимальной, если потребовать, чтобы математическое ожидание 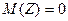 и дисперсия
и дисперсия 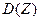 была минимальной. Первое из этих требований дает:
была минимальной. Первое из этих требований дает:
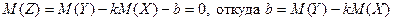 (20)
(20)
С учетом найденного значения b и (19) ошибка Z примет вид:
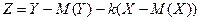
Теперь вычислим – дисперсию величины Z:
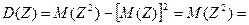
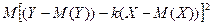 =
=
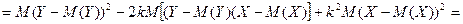
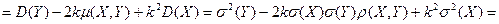

Первое из полученных слагаемых неотрицательно и не зависит от параметра k. Таким образом, дисперсия ошибки Z будет минимальной при том значении k, которое обеспечит обращение в нуль второго слагаемого. То есть при
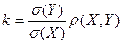 (21)
(21)
При этом дисперсия (её минимальное значение) примет вид:
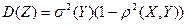 (22)
(22)
Итак, вывод: наилучшее приближение случайной величины Y линейной функцией кX+b случайной величины Х будет иметь место при значениях k и b, определяемых формулами (21) и (20). То есть такое приближение будет иметь вид:
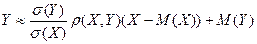 (23)
(23)
Ошибка Z этого линейного приближения величины Y имеет математическое ожидание (среднее значение), равное нулю. А дисперсия этой ошибки определяется формулой (22).
Если 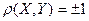 , то дисперсия ошибки
, то дисперсия ошибки 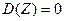 . А это, с учетом равенства означает, что
. А это, с учетом равенства означает, что 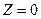 . То есть при в равенстве (23) ошибки нет и оно является точным. Но чем больше удален коэффициент линейной корреляции от , то есть чем ближе он к нулю, тем больше становится дисперсия ошибки Z, а вместе с ней тем больше становится и сама ошибка Z приближения (23). При
. То есть при в равенстве (23) ошибки нет и оно является точным. Но чем больше удален коэффициент линейной корреляции от , то есть чем ближе он к нулю, тем больше становится дисперсия ошибки Z, а вместе с ней тем больше становится и сама ошибка Z приближения (23). При 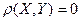 эта ошибка становится максимально возможной, а само приближение (23) принимает вид
эта ошибка становится максимально возможной, а само приближение (23) принимает вид  и перестаёт, таким образом, зависеть от X. То есть при =0 линейная зависимость Y от X отсутствует. Это значит, что или между случайными величинами X и Y вообще нет никакой связи, или они связаны, но какой-то нелинейной связью (функциональной или статистической).
и перестаёт, таким образом, зависеть от X. То есть при =0 линейная зависимость Y от X отсутствует. Это значит, что или между случайными величинами X и Y вообще нет никакой связи, или они связаны, но какой-то нелинейной связью (функциональной или статистической).
Кстати, так как наилучшим приближением случайной величины Y при X=x является, очевидно, условная средняя , то из (23) сразу вытекает наилучшее линейное приближение уравнения регрессии величины Y на величину X. Для его получения нужно в (23) заменить X на x и Y на . В итоге получим:
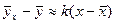 (24)
(24)
Здесь
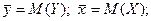 (25)
(25)
Полученное простое линейное уравнение (24) используют на практике для приближенной замены истинного уравнения регрессии , если линия регрессии близка к прямой. Если же она сильно отличается от прямой (как на рис. 2), то его тоже можно использовать, только не на всем интервале (а; b) возможных значений величины X, а на коротких частях этого интервала, на которых линию регрессии можно приближенно считать прямой.
При приближенное линейное уравнение (24) становится точным. То есть становится истинным уравнением регрессии Y на X. Более того, при этом превращается просто в y – в единственное значение Y при X=x. Это происходит потому, что при становится точным равенство (23). А это значит, что каждому значению x величины X будет соответствовать единственное значение y величины Y. И, таким образом, будет  . Линия регрессии (см. рис.2) станет прямой, и никакого разброса вокруг неё точек, изображающих возможные значения величины Y, не будет – все они окажутся на этой прямой.
. Линия регрессии (см. рис.2) станет прямой, и никакого разброса вокруг неё точек, изображающих возможные значения величины Y, не будет – все они окажутся на этой прямой.
Но если 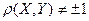 , то по мере удаления его значения от
, то по мере удаления его значения от 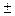 1 истинная линия регрессии или искривляется, или остается прямой, но вокруг нее появляется облако точек, причем тем более широкое, чем ближе к нулю. Или одновременно и линия регрессии искривляется, и облако точек вокруг нее расширяется. При близком к нулю или тем более равном нулю нельзя даже приближено считать величины X и Y связанными линейной корреляционной зависимостью. Связь между этими линейно некоррелированными (или слабо линейно коррелированными) случайными величинами будет или отсутствовать вообще, или будет существенно нелинейной. То есть в этом случае полученные выше формулы (23) и (24) приближенного линейного выражения одной величины (Y) через другую величину (Х) применять нельзя - они могут давать слишком грубое приближение. Тут требуется дополнительное исследование характера связи между такого рода слабо линейно коррелированными случайными величинами X и Y, которое мы проведем ниже.
1 истинная линия регрессии или искривляется, или остается прямой, но вокруг нее появляется облако точек, причем тем более широкое, чем ближе к нулю. Или одновременно и линия регрессии искривляется, и облако точек вокруг нее расширяется. При близком к нулю или тем более равном нулю нельзя даже приближено считать величины X и Y связанными линейной корреляционной зависимостью. Связь между этими линейно некоррелированными (или слабо линейно коррелированными) случайными величинами будет или отсутствовать вообще, или будет существенно нелинейной. То есть в этом случае полученные выше формулы (23) и (24) приближенного линейного выражения одной величины (Y) через другую величину (Х) применять нельзя - они могут давать слишком грубое приближение. Тут требуется дополнительное исследование характера связи между такого рода слабо линейно коррелированными случайными величинами X и Y, которое мы проведем ниже.
Перейдем к этому исследованию. То есть поставим вопрос об оценке тесноты любой, а не только линейной, корреляционной связи между случайными величинами X и Y.
Итак, допустим, что корреляционная связь между случайными величинами X и Y есть, и эта связь заведомо нелинейная (квадратичная, экспоненциальная, логарифмическая, и т. д.). Это значит, что уравнение регрессии Y на Х таково, что 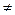
 и при этом
и при этом 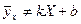 . То есть линия регрессии Y на Х – кривая линия (рис. 2). Для оценки тесноты такой криволинейной корреляционной связи между X и Y коэффициент линейной корреляции , который будет близок к нулю, не годится. В этом случае указанною тесноту оценивают с помощью так называемого корреляционного отношения.
. То есть линия регрессии Y на Х – кривая линия (рис. 2). Для оценки тесноты такой криволинейной корреляционной связи между X и Y коэффициент линейной корреляции , который будет близок к нулю, не годится. В этом случае указанною тесноту оценивают с помощью так называемого корреляционного отношения.
Чтобы ввести это понятие, рассмотрим случайную величину 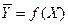 , которая является функцией величины Х и которая при Х = х принимает среднее значение величины Y. Математическое ожидание
, которая является функцией величины Х и которая при Х = х принимает среднее значение величины Y. Математическое ожидание 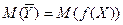 величины
величины 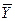 совпадает с математическим ожиданием (средним значением
совпадает с математическим ожиданием (средним значением 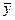 ) величины Y:
) величины Y:
 (26)
(26)
А дисперсия  величины составляет лишь часть дисперсии
величины составляет лишь часть дисперсии 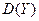 величины Y:
величины Y:
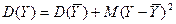 (27)
(27)
При доказательстве равенств (26) и (27) ограничимся случаем, когда X и Y – дискретные случайные величины.
Итак, пусть X и Y – зависимые дискретные случайные величины, а таблица (28) – закон их совместного распределения:
| X Y | х
| х
| ............ | х
| q 
| (28) |
| y
| p
| p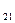
| ............ | p
| q
| |
| y
| p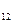
| p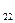
| ............ | p
| q
| |
| ....... | ....... | ....... | ............ | ....... | ....... | |
y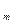
| p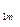
| p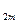
| ............ | p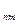
| q
| |
| pi | p
| p
| ............ | p
|
Здесь (x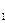 , x,… x) и (y, y,…y) – возможные значения величин X и Y соответственно, а
, x,… x) и (y, y,…y) – возможные значения величин X и Y соответственно, а 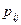 - вероятности того, что в результате испытания парой случайных величин будет принята пара значений
- вероятности того, что в результате испытания парой случайных величин будет принята пара значений 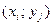
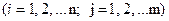 . Кстати, сумма всех вероятностей , как сумма вероятностей событий, составляющих полную группу событий, должна равняться единице:
. Кстати, сумма всех вероятностей , как сумма вероятностей событий, составляющих полную группу событий, должна равняться единице:
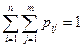 (29)
(29)
Действительно, события, состоящие в том, что 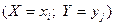 , являются несовместными. Причем одно из них обязательно произойдет. То есть эти события действительно образуют полную группу событий.
, являются несовместными. Причем одно из них обязательно произойдет. То есть эти события действительно образуют полную группу событий.
В последней строке таблицы (28) просуммированы вероятности по строкам (внутри каждого столбца). А в последнем столбце этой таблицы просуммированы вероятности по столбцам (внутри каждой строки):
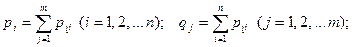
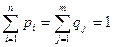 (30)
(30)
Вероятности 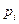 - это, очевидно, вероятности значений
- это, очевидно, вероятности значений  величины X, а вероятности
величины X, а вероятности  - это вероятности значений
- это вероятности значений 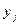 величины Y. То есть на базе закона совместного распределения случайных величин X и Y можно записать и законы распределения каждой из этих величин в отдельности:
величины Y. То есть на базе закона совместного распределения случайных величин X и Y можно записать и законы распределения каждой из этих величин в отдельности:

| 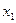
| 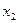
| … | 
| 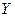
| 
| 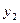
| … | 
| (31) | |
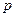
| 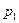
| 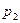
| … | 
|
| 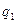
| 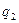
| … | 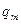
|
Среднее значение 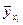 величины Y для каждого возможного значения величины Y следует находить по формуле:
величины Y для каждого возможного значения величины Y следует находить по формуле:
 (32)
(32)
Действительно, согласно (4)
 (33)
(33)
То есть - это условное математическое ожидание величины Y при X =. А следовательно, оно должно быть найдено как сумма произведений значений величины Y на соответствующее им вероятности этих значений при условии, что X =. То есть
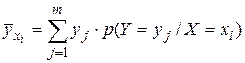 (34)
(34)
А условные вероятности 
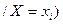 можно найти из формулы вероятности произведения двух зависимых событий:
можно найти из формулы вероятности произведения двух зависимых событий:
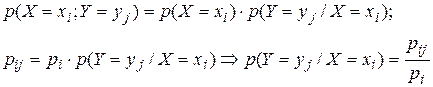 (35)
(35)
Из формул (34) и (35) и следует формула (32).
Подсчитав значения , можем составить и закон распределения случайной величины 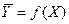 :
:
|
| 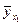
| 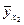
| … | 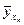
| (36) |
|
|
|
| … |
|
(вероятности значений величины 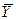 те же, что и вероятности значений величины X).
те же, что и вероятности значений величины X).
Ну, а теперь можем перейти к доказательству равенств (26) и (27). Сначала докажем (26):
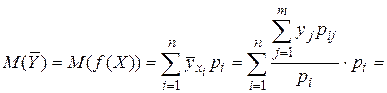
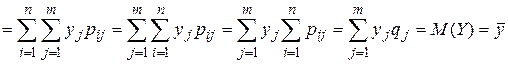 (37)
(37)
Равенство (26) доказано.
Для доказательства равенства (27) образует случайную величину 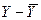 и запишем закон её распределения:
и запишем закон её распределения:
|
| 
|  (38) (38)
|
|
|
|
Математическое ожидание этой случайной величины равно нулю - это следует из (26). Покажем ещё, что
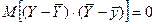 (39)
(39)
Закон распределения случайной величины  имеет вид:
имеет вид:

| 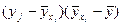
| (40)
|
|
|
|
Отсюда следует:

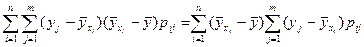 =
=
= 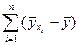
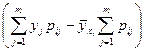 =
= 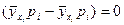 . (41)
. (41)
А теперь, опираясь на доказанные равенства (6.24) и (6.37), можно доказать и равенство (27):
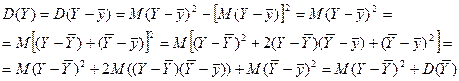
Равенство (27) доказано. Это равенство дает разложение общей дисперсии зависимой от X случайной величины Y на сумму двух слагаемых: дисперсии функции и среднего квадрата отклонения Y от этой функции. Иначе говоря, общий разброс значений у величины Y вокруг её среднего значения складывается из разброса значений величины вокруг того же , и разброса значений у вокруг . То есть формула (27) раскладывает общий разброс всех возможных значений y величины Y вокруг её математического ожидания 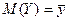 на разброс вокруг точек
на разброс вокруг точек 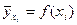 кривой регрессии, и на разброс значений у (облака точек, изображающих значения y) вокруг кривой регрессии
кривой регрессии, и на разброс значений у (облака точек, изображающих значения y) вокруг кривой регрессии 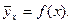
Введем теперь отношение
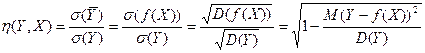 (42)
(42)
которое будет называть корреляционным отношением Y к X. Очевидно, что всегда
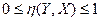 (43)
(43)
Из определения 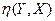 следует, что =0 при
следует, что =0 при 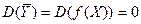 , то есть при условии, что =Const. Причем эта константа, естественно, равна . Но тогда уравнение регрессии Y на X имеет вид =и, следовательно, случайная величина Y не зависит корреляционно (в среднем) от величины X. А если
, то есть при условии, что =Const. Причем эта константа, естественно, равна . Но тогда уравнение регрессии Y на X имеет вид =и, следовательно, случайная величина Y не зависит корреляционно (в среднем) от величины X. А если 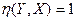 , то в этом случае из (42) следует, что
, то в этом случае из (42) следует, что  =0, откуда вытекает, что
=0, откуда вытекает, что 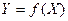 . То есть при случайные величины X и Y связаны жесткой функциональной зависимостью , причем
. То есть при случайные величины X и Y связаны жесткой функциональной зависимостью , причем 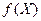 Const.
Const.
Из сказанного следует, что чем ближе корреляционное отношение к единице, тем ближе корреляционная зависимость Y от X к функциональной зависимости. А это значит, тем эта корреляционная зависимость теснее. Наоборот, чем ближе к нулю, тем она слабее.
Таким образом, корреляционное отношение случайной величины Y к случайной величине X является мерой и наличия, и тесноты любой (а не только линейной) корреляционной зависимости величины Y от величины X.
Естественно, можно ввести в рассмотрение и корреляционное отношение 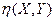 величины X к величине Y.
величины X к величине Y.
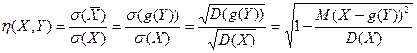 (44)
(44)
которое оценивает наличие и тесноту корреляционной зависимости величины X от Y, где - уравнение регрессии X на Y.
Отметим, что в отличие от коэффициента линейной корреляции, которой симметричен относительно X и Y (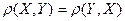 ), корреляционное отношение таким свойством, судя по (42) и (44), не обладает:
), корреляционное отношение таким свойством, судя по (42) и (44), не обладает:
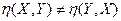 (45)
(45)
Можно еще доказать, что всегда
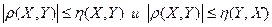 (46)
(46)
При этом в случае равенства
 (47)
(47)
имеет место точная линейная корреляционная зависимость Y от X. Это значит, что при условии (49) приближенное уравнение регрессии (24) Y на X становится точным.
Аналогично в случае
 (48)
(48)
становится точным соответствующее уравнение регрессии 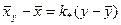 X на Y.
X на Y.
Пример 4. Дискретные случайные величины X и Y заданы следующим законом их совместного распределения:
 X
Y X
Y
| 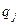
| |||
| 0,10 | 0,16 | 0,18 | 0,44 | |
| 0,06 | 0,20 | 0,30 | 0,56 | |
|
| 0,16 | 0,36 | 0,48 |
Требуется:
1) Найти коэффициент линейной корреляции .
2) Найти корреляционное отношение .
3) Построить линию регрессии величины Y на величину X.
Решение. Запишем сначала законы распределения величин X и Y по отдельности:
| X | Y | ||||||
| р | 0,16 | 0,36 | 0,48 | р | 0,44 | 0,56 |
Отсюда, в частности, следует (получите это самостоятельно):

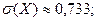
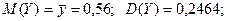
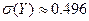 ;
;
Теперь найдем . Для этого, согласно (6.7), предварительно нужно найти корреляционный момент 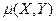 . Его найдем по формуле (7), используя совместный закон распределения (таблицу) величины Х и Y:
. Его найдем по формуле (7), используя совместный закон распределения (таблицу) величины Х и Y:
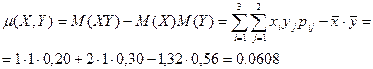
Тогда:
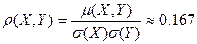
Величина . Таким образом, величины X и Y линейно коррелированы, а значит и зависимы. Вместе с тем величина невелика (она гораздо ближе к нулю, чем к 1 или к -1). Поэтому корреляционная зависимость Y от Х или слабая, или существенно нелинейная, или то и другое вместе.
Чтобы лучше выяснить этот вопрос, подсчитаем корреляционное отношение величины Y к величине Х. Для этого сначала для каждого значения х величины Х подсчитаем среднее значение величины Y. Используя формулы (32), получим:
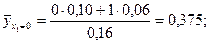
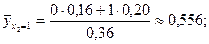
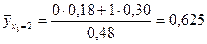
Полученные данные позволяют записать таблицу вида (36) - закон распределения функции случайной величины Х:
|
| 0,375 | 0,556 | 0,625 |
| р | 0,16 | 0,36 | 0,48 |
Из этой таблицы находим:
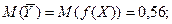
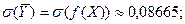
=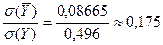 .
.
Величина оказалась большей, чем - так и должно, согласно (46), быть. Однако и она невелика, что свидетельствует о малой тесноте корреляционной зависимости Y и X. А так как различие между и незначительное, то корреляционная зависимость Y от X близка к линейной.
Этот вывод должна подтвердить линия регрессии . Ее следует строить по трем точкам:
|
| |||
|
| 0,375 | 0,556 | 0,625 |
Как легко убедиться, ломаная, соединяющая эти три точки, действительна близка к прямой линии.
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 13854; Нарушение авторских прав?; Мы поможем в написании вашей работы!