КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Найменших квадратів
|
|
|
|
Гетероскедастичність. Узагальнений метод
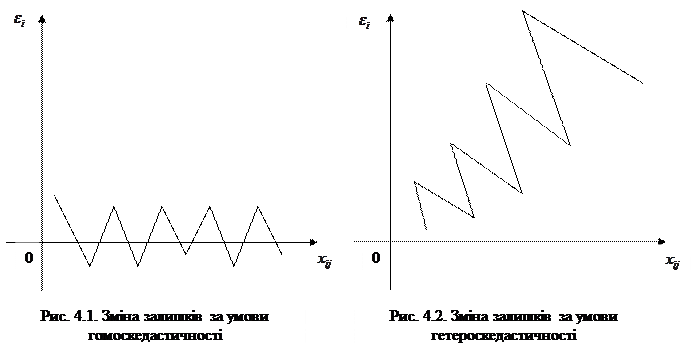
У п.4.3 відзначалося, що одним із припущень при побудові класичної регресійної моделі є постійна дисперсія залишків (гомоскедастичність), тобто дисперсійно-коваріаційна матриця вектора випадкових величин має вигляд (4.8). Таке припущення є достатньо логічним за умови, що дані статистичних спостережень однорідні і діапазон їх варіації невеликий.
Випадкова величина 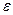 відображає у моделі вплив на залежну змінну неврахованих факторів, які можуть змінюватися в одинаковому з пояснювальними змінними напрямку, що призводить до збільшення відхилень фактичних даних від лінії регресії. Якщо дисперсія випадкової величини змінюється із зміною значень пояснювальних змінних (не виконується припущення про сталість дисперсії), то має місце явище, яке носить назву гетероскедастичності.
відображає у моделі вплив на залежну змінну неврахованих факторів, які можуть змінюватися в одинаковому з пояснювальними змінними напрямку, що призводить до збільшення відхилень фактичних даних від лінії регресії. Якщо дисперсія випадкової величини змінюється із зміною значень пояснювальних змінних (не виконується припущення про сталість дисперсії), то має місце явище, яке носить назву гетероскедастичності.
Типовим прикладом зміни дисперсії випадкової величини слугує залежнітсь витрат на споживання від рівня доходів. Очевидно, що варіація у поведінці витрат в осіб з високим рівнем доходів буде вищою, ніж в осіб з малими доходами.
Графічна ілюстрація випадків гомоскедастичності і гетероскедастичності показана на рис.4.1 і рис.4.2.
Якщо має місце гетероскедастичність, то оцінки параметрів моделі, отримані за допомогою 1МНК, будуть незміщеними, обґрунтованими, але неефективними (дисперсії оцінок параметрів регресійної моделі за умови гетероскедастичності є більшими за дисперсії оцінок за умови гомоскедастичності, а отже інтервали оцінок також будуть більшими). А це означає, що застосування 1МНК у випадку гетероскедастичності дає зміщену оцінку дисперсійно-коваріаційної матриці (4.28) вектора оцінок 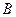 . Як наслідок,
. Як наслідок, 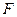 -критерій та
-критерій та 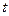 -критерії дають неточні результати, а параметри моделі виявляються статистично незначущими.
-критерії дають неточні результати, а параметри моделі виявляються статистично незначущими.
Умова гомоскедастичності на практиці часто порушується і, якщо на неї не звертати уваги (застосовуючи 1МНК і звичайні процедури перевірки гіпотез), то можна отримати помилкові результати. У зв’язку з цим виникає проблема з’ясування наявності або відсутності у масиві спостережень гетероскедастичності. Як і у випадку мультиколінеарності, однозначних підходів до виявлення гетероскедастичності не існує.
У деяких випадках гетероскедастичність виявляється інтуїтивно або висувається як гіпотеза. Наприклад, фірми з високим рівнем прибутковості проводять більш ризиковану дивідендну політику, ніж фірми, які отримують малі прибутки.
Простим та наочним є графічний метод виявлення гетероскедастичності, зміст якого полягає у візуальному аналізі залежності між пояснюваною змінною 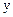 та квадратами залишків
та квадратами залишків 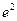 , або між будь-якою пояснювальною змінною
, або між будь-якою пояснювальною змінною 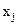 та . Графічний аналіз, не зважаючи на певну суб’єктивність зі сторони дослідника, у деяких випадках дає змогу не тільки встановити наявність гетероскедастичності, а й зробити висновок про форму зв’язку.
та . Графічний аналіз, не зважаючи на певну суб’єктивність зі сторони дослідника, у деяких випадках дає змогу не тільки встановити наявність гетероскедастичності, а й зробити висновок про форму зв’язку.
Розроблено декілька кількісних методів тестування гетероскедастичності, які в якості нульової гіпотези 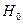 використовують гіпотезу про відсутність гетероскедастичності.
використовують гіпотезу про відсутність гетероскедастичності.
Якщо кількість спостережень хоча б у два рази перевищує кількість параметрів моделі і залишки рівняння регресії можна вважати нормально розподіленими, то можна скористатися тестом Гольдфельда-Квандта. Реалізація цього тесту ставить ще одну вимогу, згідно якої 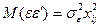 , тобто дисперсія залишків зростає пропорційно квадрату однієї із пояснювальних змінних. Процедура тестування полягає у виконанні наступних кроків:
, тобто дисперсія залишків зростає пропорційно квадрату однієї із пояснювальних змінних. Процедура тестування полягає у виконанні наступних кроків:
1. Спостереження (обсяг вибірки рівний  ) впорядковуються за зростанням значень пояснювальної змінної .
) впорядковуються за зростанням значень пояснювальної змінної .
2. Вибирається  центральних спостережень, що забезпечує порівняння дисперсій для найменших і найбільших значень змінної . Для вибірок
центральних спостережень, що забезпечує порівняння дисперсій для найменших і найбільших значень змінної . Для вибірок 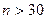 автори рекомендують вибирати величину неврахованих центральних спостережень згідно співвідношення:
автори рекомендують вибирати величину неврахованих центральних спостережень згідно співвідношення:
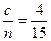 .
.
3. Залишок 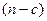 спостережень поділяється на дві підвибірки однакового розміру:
спостережень поділяється на дві підвибірки однакового розміру:
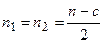 ,
,
причому значення 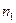 і
і 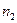 перевищують кількість змінних
перевищують кількість змінних 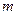 (якщо
(якщо 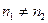 , то відкидається одне із крайніх спостережень).
, то відкидається одне із крайніх спостережень).
4. Для кожної із підвибірок будують економетричні моделі за допомогою 1МНК і знаходять суми квадратів залишків 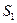 і
і 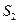 :
:
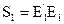 ;
;
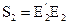 ,
,
де 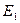 і
і 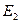 - відповідно вектори залишків, отриманих за першою і другою моделями.
- відповідно вектори залишків, отриманих за першою і другою моделями.
5. Обчислюють відношення
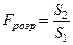 ,
,
яке у випадку гетероскедастичності має -розподіл з 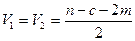 ступенями вільності.
ступенями вільності.
6. Для вибраного рівня значущості 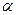 знаходять критичне значення -критерію
знаходять критичне значення -критерію 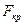 і порівнюють з розрахунковим. Якщо
і порівнюють з розрахунковим. Якщо 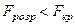 , то приймається гіпотеза про відсутність гетероскедастичності.
, то приймається гіпотеза про відсутність гетероскедастичності.
Застосуємо тест Гольдфельда-Квандта для дослідження наявності гетероскедастичності у масиві даних, поданих у табл.4.4.
Допустимо, що гетероскедастичність залишків може викликати змінна 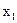 , а тому сортуємо вхідну інформацію у порядку зростання (витрат на оплату праці).
, а тому сортуємо вхідну інформацію у порядку зростання (витрат на оплату праці).
Вилучаємо  центральних спостережень і отримуємо дві підвибірки, які будемо досліджувати.
центральних спостережень і отримуємо дві підвибірки, які будемо досліджувати.
Застосовуємо 1МНК і отримуємо результати, представлені у табл.4.5.
Таблиця 4.5
| Група |
|
| 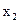
| 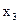
| 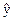
| 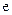
| 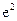
|
| І | 14,99 | 122,6419 | -0,64186 | 0,411988 | |||
| 15,01 | 123,5236 | 0,476354 | 0,226913 | ||||
| 14,62 | 124,4296 | 0,42958 | 0,18454 | ||||
| 14,41 | 125,9295 | 1,070458 | 1,14588 | ||||
| 23,71 | 124,0948 | -0,09482 | 0,008991 | ||||
| 15,42 | 129,0949 | -1,09484 | 1,198681 | ||||
| 17,44 | 128,2857 | 0,714297 | 0,510221 | ||||
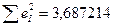 Рівняння регресії:
Рівняння регресії:
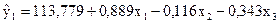
| |||||||
| ІІ | 9,87 | 132,4699 | -1,46988 | 2,160554 | |||
| 8,94 | 132,0012 | 0,998812 | 0,997625 | ||||
| 12,53 | 137,3836 | -0,38355 | 0,147113 | ||||
| 9,47 | 131,0322 | -0,03215 | 0,001034 | ||||
| 12,03 | 135,9293 | 1,070745 | 1,146495 | ||||
| 11,23 | 137,8969 | 0,103129 | 0,010636 | ||||
| 11,67 | 139,2871 | -0,2871 | 0,082426 | ||||
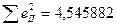 Рівняння регресії:
Рівняння регресії:
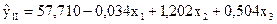
|
В результаті отримуємо розрахункове значення критерію:
 .
.
З таблиць розподілу для рівня значущості  і
і 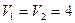 ступенів вільності знаходимо
ступенів вільності знаходимо 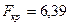 . Так як
. Так як 
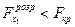 , то змінна не викликає гетероскедастичності залишків.
, то змінна не викликає гетероскедастичності залишків.
У табл.4.6 і 4.7 подані проміжні результати дослідження гетероскедастичності залишків, зумовлених впливом відповідно змінних та .
Розрахункові значення критеріїв рівні:
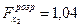 ;
;
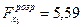 .
.
Таблиця 4.6
| Група |
|
|
|
|
|
|
|
| І | 23,71 | 124,0329 | -0,03289 | 0,001082 | |||
| 14,99 | 123,2003 | -1,20034 | 1,440828 | ||||
| 15,01 | 123,5982 | 0,401793 | 0,161438 | ||||
| 14,62 | 124,1824 | -0,18244 | 0,033285 | ||||
| 14,41 | 125,4058 | 1,594229 | 2,541565 | ||||
| 10,02 | 130,2566 | -0,25656 | 0,065825 | ||||
| 15,42 | 128,3238 | -0,32378 | 0,104835 | ||||
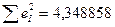 Рівняння регресії:
Рівняння регресії:
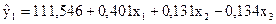
| |||||||
| ІІ | 9,87 | 132,5078 | -1,50782 | 2,273509 | |||
| 8,94 | 132,0341 | 0,96587 | 0,932905 | ||||
| 8,53 | 132,9658 | 0,034239 | 0,001172 | ||||
| 12,03 | 135,9503 | 1,049653 | 1,101772 | ||||
| 12,53 | 137,3455 | -0,34548 | 0,119354 | ||||
| 11,23 | 137,8852 | 0,114768 | 0,013172 | ||||
| 11,67 | 139,3112 | 0,31124 | 0,196869 | ||||
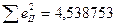 Рівняння регресії:
Рівняння регресії:
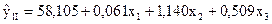
|
Таблиця 4.7
| Група |
|
|
|
|
|
|
|
| І | 8,53 | 133,1483 | -0,14832 | 0,022 | |||
| 8,94 | 132,4167 | 0,583348 | 0,340295 | ||||
| 9,47 | 131,431 | -0,43103 | 0,185786 | ||||
| 9,63 | 131,2853 | -0,28533 | 0,081416 | ||||
| 9,87 | 130,9297 | 0,070327 | 0,004946 | ||||
| 10,02 | 129,9286 | 0,071374 | 0,005094 | ||||
| 10,53 | 129,8604 | 0,13964 | 0,019499 | ||||
 Рівняння регресії:
Рівняння регресії:
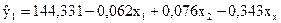
| |||||||
| ІІ | 14,41 | 125,9295 | 1,070458 | 1,14588 | |||
| 14,62 | 124,4296 | -0,42958 | 0,18454 | ||||
| 14,99 | 122,6419 | -0,64186 | 0,411988 | ||||
| 15,01 | 123,5236 | 0,476354 | 0,226913 | ||||
| 15,42 | 129,0948 | -1,09484 | 1,198681 | ||||
| 17,44 | 128,2857 | 0,714297 | 0,510221 | ||||
| 23,71 | 124,0948 | -0,09482 | 0,008991 | ||||
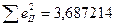 Рівняння регресії:
Рівняння регресії:
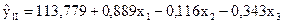
|
Вони не перевищують критичне, а тому слід прийняти гіпотезу про те, що зміна дисперсії залишків не зумовлюється зміною та .
Таким чином, будемо вважати, що тест Гольдфельда-Квандта не виявив гетероскедастичності у масиві спостережень, представлених у табл.4.4.
Для виявлення гетероскедастичності у достатньо великому масиві спостережень можна використати 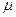 -критерій, алгоритм якого передбачає реалізацію таких кроків:
-критерій, алгоритм якого передбачає реалізацію таких кроків:
1. Вхідні дані вектора 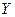 розбивають на
розбивають на 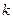 груп
груп 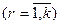 .
.
2. Для кожної групи спостережень розраховують суму квадратів відхилень:
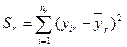 ,
,
де 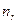 - кількість спостережень в
- кількість спостережень в 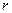 -ій групі.
-ій групі.
3. Розраховується сума квадратів відхилень для всієї сукупності:
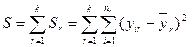 .
.
4. Знаходять параметр 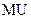 :
:
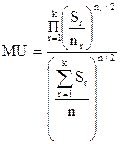 ,
,
де - загальна кількість спостережень.
5.Обчислюється значення -критерію:
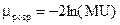 .
.
Величина 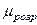 є наближеним значенням
є наближеним значенням 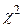 у випадку, коли дисперсія всіх спостережень є однорідною при
у випадку, коли дисперсія всіх спостережень є однорідною при 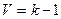 ступені вільності. Якщо для вибраного значення рівня значущості критичне (табличне) значення розподілу
ступені вільності. Якщо для вибраного значення рівня значущості критичне (табличне) значення розподілу 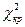 є меншим за , то слід прийняти гіпотезу про наявність у досліджуваній сукупності явища гетероскедастичності.
є меншим за , то слід прийняти гіпотезу про наявність у досліджуваній сукупності явища гетероскедастичності.
Ще одним із тестів перевірки гетероскедастичності є тест Глейзера, який базується на побудові регресійної функції, що описує залежність між абсолютною величиною залишків, отриманих згідно 1МНК, і незалежною змінною 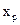 , яка зумовлює зміну залишків:
, яка зумовлює зміну залишків:
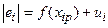
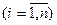 .
.
В якості регресійної функції, як правило, вибирається така форма зв’язку:
а) 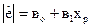 ; б)
; б) 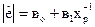 ;
;
в) 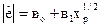 ; г)
; г) 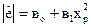 .
.
Будуються регресійні рівняння для різних форм зв’язку, після чого вибирається функція з найбільшим значенням 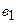 (має найбільше значення -статистики). Наявність чи відсутність гетероскедастичності приймається на основі статистичної значущості параметрів моделі, для чого можна скористатися одним із стандартних методів (наприклад, -тестом або -тестом). Можливі чотири ситуації:
(має найбільше значення -статистики). Наявність чи відсутність гетероскедастичності приймається на основі статистичної значущості параметрів моделі, для чого можна скористатися одним із стандартних методів (наприклад, -тестом або -тестом). Можливі чотири ситуації:
1)  і
і 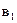 - статистично значущі (має місце чиста і змішана гетероскедастичність);
- статистично значущі (має місце чиста і змішана гетероскедастичність);
2) - статистично значущий, а - статистично незначущий (залишки мають змішану гетероскедастичність);
3) - статистично незначущий, а - статистично значущий (залишки мають чисту гетероскедастичність);
4) і - статистично незначущі (гетероскедастичність відсутня).
Змішана гетероскедастичність пов’язується із зміною пояснювальних змінних, які не включені до моделі, але впливають на залежну змінну.
Суттєвою перевагою тесту Глейзера порівняно з іншими тестами для перевірки гетероскедастичності є те, що отримується інформація про форму зв’язку між дисперсією залишків і незалежною змінною, яка є важливою у процесі вилучення гетероскедастичності. Слід зауважити, що при застосуванні тесту Глейзера можлива помилка специфікації рівняння регресії залишків від пояснювальної змінної.
Застосуємо тест Глейзера до масиву даних, поданих у табл.4.4.
За допомогою 1МНК будуємо рівняння множинної лінійної регресії:
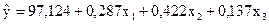 .
.
Підставляємо у рівняння регресії значення пояснювальних змінних і знаходимо залишки (табл.4.8).
Таблиця 4.8
|
|
|
|
|
|
| 
|
| 10,53 | 132,5175 | -2,517531 | 2,517531 | |||
| 15,42 | 129,7923 | -1,792266 | 1,792266 | |||
| 12,98 | 130,5899 | -1,589938 | 1,589938 | |||
| 9,63 | 131,6855 | -0,685535 | 0,685535 | |||
| 23,71 | 124,7112 | -0,711193 | 0,711193 | |||
| 12,53 | 135,0536 | 1,946434 | 1,946434 | |||
| 17,44 | 130,4908 | -1,490807 | 1,490807 | |||
| 14,41 | 124,8424 | 2,157577 | 2,157577 | |||
| 14,99 | 122,086 | -0,085965 | 0,085965 | |||
| 8,53 | 133,3754 | -0,375363 | 0,375363 | |||
| 9,47 | 132,9458 | -1,945781 | 1,945781 | |||
| 12,03 | 134,5629 | 2,437147 | 2,437147 | |||
| 15,01 | 122,3753 | 1,624709 | 1,624709 | |||
| 14,62 | 123,0309 | 0,969093 | 0,969093 | |||
| 10,02 | 128,9332 | 1,066751 | 1,066751 | |||
| 12,33 | 130,9234 | 1,923413 | 1,923413 | |||
| 9,87 | 133,1362 | -2,13623 | 2,13623 | |||
| 8,94 | 133,0091 | -0,009072 | 0,009072 | |||
| 11,23 | 135,5848 | 2,415241 | 2,415241 | |||
| 11,67 | 136,3539 | 2,64614 | 2,64614 |
Знаходимо залежності між модулями залишків та кожною із пояснювальних змінних (результати представлені у табл.4.9). З таблиць розподілу для і 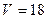 ступенів вільності отримуємо
ступенів вільності отримуємо 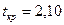 . Якщо порівнювати критичне значення -критерію із розрахунковими значеннями -статистики коефіцієнтів рівняння регресії, то із табл.4.9 видно, що статистично значущими є лише вільні члени деяких функцій, тобто можна говорити про змішану гетероскедастичність. Вона зумовлена дією пояснювальних змінних, які не включені до моделі.
. Якщо порівнювати критичне значення -критерію із розрахунковими значеннями -статистики коефіцієнтів рівняння регресії, то із табл.4.9 видно, що статистично значущими є лише вільні члени деяких функцій, тобто можна говорити про змішану гетероскедастичність. Вона зумовлена дією пояснювальних змінних, які не включені до моделі.
Таблиця 4.9
 Змінна
Функція Змінна
Функція
|
|
|
|
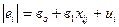
| 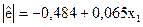 (-0,43)*; (1,79)
(-0,43)*; (1,79)
| 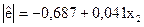 (-0,60); (1,95)
(-0,60); (1,95)
|  (2,56); (-0,43)
(2,56); (-0,43)
|
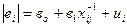
|  (3,30); (-1,75)
(3,30); (-1,75)
| 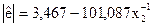 (3,37); (-1,91)
(3,37); (-1,91)
| 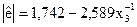 (2,08); (-0,26)
(2,08); (-0,26)
|
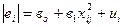
| 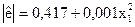 (0,66); (1,81)
(0,66); (1,81)
| 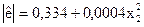 (0,53); (1,97)
(0,53); (1,97)
| 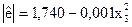 (4,90); (-0,71)
(4,90); (-0,71)
|
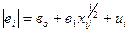
| 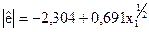 (-1,07); (1,78)
(-1,07); (1,78)
| 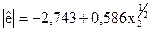 (-1,24); (1,94)
(-1,24); (1,94)
| 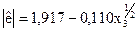 (1,31); (-0,26)
(1,31); (-0,26)
|
* У дужках вказано розрахункове значення -статистики коефіцієнтів рівняння регресії
Висновки, зроблені щодо наявності або відсутності гетероскедастичності за допомогою різних тестів, можуть відрізнятися, так як кожний із тестів базується на певних припущеннях.
За умови наявності гетероскедастичності модель (4.4) називається узагальненою лінійною моделлю множинної регресії. Від класичної моделі вона відрізняється видом дисперсійно-коваріаційної матриці залишків (нагадаємо, що для класичної моделі має місце (4.8), тобто  ). Для оцінювання параметрів узагальненої моделі використовують узагальнений метод найменших квадратів (УМНК), який називають також методом Ейткена. Ідея методу Ейткена полягає у трансформації (зміні) початкової моделі таким чином, щоб дисперсії залишків стали постійними.
). Для оцінювання параметрів узагальненої моделі використовують узагальнений метод найменших квадратів (УМНК), який називають також методом Ейткена. Ідея методу Ейткена полягає у трансформації (зміні) початкової моделі таким чином, щоб дисперсії залишків стали постійними.
Характер трансформації моделі визначається формою гетероскедастичності – формою залежності між дисперсією залишків і значеннями пояснювальних змінних.
Для трансформації моделі можна скористатися значеннями 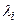 , які обчислюють згідно із таких можливих припущень:
, які обчислюють згідно із таких можливих припущень:
а) дисперсія залишків пропорційна до зміни пояснювальної змінної :
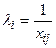 ;
;
б) дисперсія залишків пропорційна до зміни квадрата пояснювальної змінної :
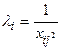 ;
;
в) дисперсія залишків пропорційна до зміни квадрата залишків за абсолютною величиною (модулем):
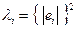 .
.
Якщо припущення про сталість дисперсії залишків не виконується, то 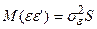 , при цьому змінюються лише дисперсії залишків, а коваріація між ними відсутня. Матриця
, при цьому змінюються лише дисперсії залишків, а коваріація між ними відсутня. Матриця
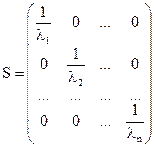 ,
,
сформована на основі значень 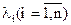 , є діагональною і додатно визначеною. Її можна представити у вигляді
, є діагональною і додатно визначеною. Її можна представити у вигляді 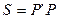 , де
, де
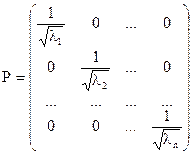 .
.
Оберненою до матриці 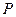 є матриця
є матриця 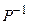 :
:
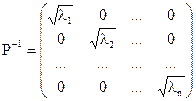 .
.
Нехай економетрична модель представлена у вигляді (4.4) і . Так як є не виродженою матрицею, то
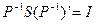 (4.72)
(4.72)
і
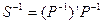 (4.73)
(4.73)
Помножимо обидві частини (4.4) ліворуч на матрицю :
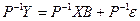 . (7.74)
. (7.74)
Якщо прийняти позначення
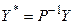 ;
; 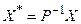 ;
; 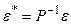 ,
,
то економетрична модель запишеться у вигляді:
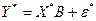 . (4.75)
. (4.75)
Модель (4.75) задовольняє вимоги класичної лінійної моделі множинної регресії:
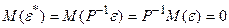 , так як
, так як 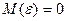 ;
;
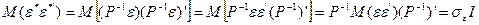 , так як має місце (4.72).
, так як має місце (4.72).
Таким чином, керуючись теоремою Гауса-Маркова, приходимо до висновку, що оцінка
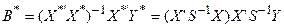 (4.76)
(4.76)
є найбільш ефективною оцінкою в класі лінійних незміщених оцінок.
Дисперсійно-коваріаційна матриця оцінок вектора рівна:
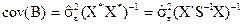 . (4.77)
. (4.77)
Незміщену оцінку дисперсії  розраховують згідно формули:
розраховують згідно формули:
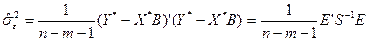 . (4.78)
. (4.78)
Користуючись (4.76) і (4.77), можна застосовувати стандартні тести для перевірки значущості і знайти довірчі інтервали для оцінок параметрів моделі.
Вище за допомогою тесту Глейзера у масиві даних табл.4.4 було виявлено змішану гетероскедастичність. Зокрема, на змішану гетероскедастичність вказує економетрична модель залишків
,
в якій оцінка 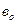 є статистично значущою. Підставимо у цю модель фактичні значення змінної і отримаємо розрахункові значення модулів залишків та їх квадрати. Позначимо:
є статистично значущою. Підставимо у цю модель фактичні значення змінної і отримаємо розрахункові значення модулів залишків та їх квадрати. Позначимо: 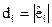 і
і 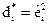 .
.
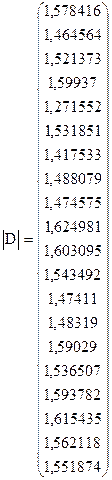
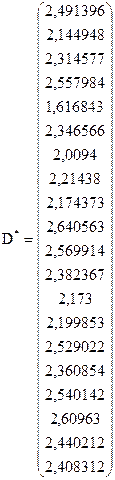
Для побудови матриць 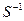 і
і 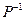 скористаємося співвідношенням
скористаємося співвідношенням 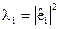 . Тоді значення вектора
. Тоді значення вектора 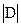 будуть діагональними елементами матриці , а значення вектора
будуть діагональними елементами матриці , а значення вектора 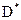 - діагональними елементами матриці .
- діагональними елементами матриці .
Використовуючи (4.76), знайдемо оцінки параметрів рівняння лінійної множинної регресії методом Ейткена:
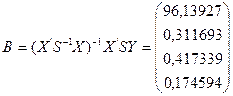 .
.
Рівняння регресії має вигляд:
 .
.
Згідно 1МНК рівняння буде таким:
.
Як бачимо, результати отримані за допомогою 1МНК і методу Ейткена, дещо різняться. Так як має місце гетероскедастичність, то можна вважати, що метод Ейткена дає більш точні кількісні оцінки параметрів економетричної моделі.
При розрахунку точкового прогнозу необхідно враховувати систематичну складову, пов’язану із залишками. Не вдаючись до строгих досліджень, сформулюємо лише основні положення побудови прогнозів на базі економетричних моделей, параметри яких оцінені УМНК.
Припустимо, що у прогнозованому періоді пояснювальні змінні приймуть значення 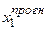 ,
, 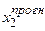 , …,
, …,  , а оцінки параметрів моделі множинної лінійної регресії
, а оцінки параметрів моделі множинної лінійної регресії 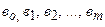 знайдено за допомогою УМНК. Тоді точковий прогноз за наявності гетероскедастичності розраховують згідно формули:
знайдено за допомогою УМНК. Тоді точковий прогноз за наявності гетероскедастичності розраховують згідно формули:
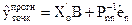 , (4.79)
, (4.79)
де 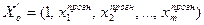 ;
;
- вектор оцінок параметрів моделі (отриманий за методом Ейткена);
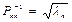 - останній діагональний елемент матриці
- останній діагональний елемент матриці 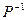 ;
;
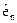 - останній елемент вектора залишків, отриманих за допомогою 1МНК.
- останній елемент вектора залишків, отриманих за допомогою 1МНК.
Інтервальний прогноз 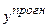 буде міститися у проміжку:
буде міститися у проміжку:
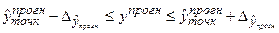 , (4.80)
, (4.80)
де 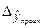 - гранична похибка прогнозу.
- гранична похибка прогнозу.
Граничну похибку прогнозу розраховують за допомогою виразу:
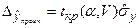 , (4.81)
, (4.81)
де 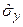 - оцінка середньоквадратичної (стандартної) похибки прогнозу, яка обчислюється згідно співвідношення (4.82):
- оцінка середньоквадратичної (стандартної) похибки прогнозу, яка обчислюється згідно співвідношення (4.82):
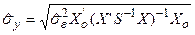 . (4.82)
. (4.82)
Оцінка дисперсії випадкової величини, яка фігурує у (4.82) рівна:
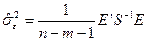 , (4.83)
, (4.83)
де 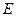 - вектор залишків, який відповідає оцінці параметрів моделі на основі 1МНК.
- вектор залишків, який відповідає оцінці параметрів моделі на основі 1МНК.
Припустимо, що у прогнозному періоді витрати на оплату праці, на сировину і матеріали та транспортно-заготівельні витрати будуть становити (тис.грн.):
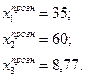
Тоді
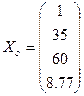 .
.
Підставивши у (4.79) знайдений вище за допомогою методу Ейткена вектор оцінок , вектор 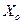 і значення
і значення 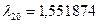 і
і 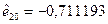 , отримаємо точковий прогноз обсягу виконаних будівельно-монтажних робіт:
, отримаємо точковий прогноз обсягу виконаних будівельно-монтажних робіт:
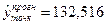 (тис.грн.).
(тис.грн.).
Для того, щоб знайти інтервальний прогноз, використаємо (4.81). Послідовно знаходимо
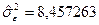 .
.
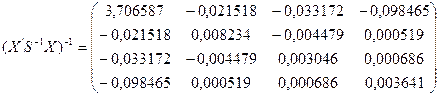 .
.
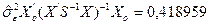 .
.
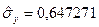 .
.
З таблиць розподілу для і 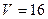 ступенів вільності маємо
ступенів вільності маємо  . Прогнозне значення обсягу виконаних будівельно-монтажних робіт буде знаходитися в межах:
. Прогнозне значення обсягу виконаних будівельно-монтажних робіт буде знаходитися в межах:
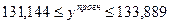 (тис.грн.).
(тис.грн.).
|
|
|
|
|
Дата добавления: 2014-12-16; Просмотров: 3122; Нарушение авторских прав?; Мы поможем в написании вашей работы!